Парсер – программа для получения ("парсинга") каких-либо данных из какого-нибудь источника. В качестве источника данных могут выступать публично доступные ресурсы, например, веб-сайты или RSS-рассылки; либо базы данных или удаленные API-интерфейсы, предоставляющие доступ к структурированной информации только через авторизацию; а также загружаемые пользователем данные.
Парсер может быть и отдельно распространяемым приложением, работающим в какой-то одной определенной операционной системе, и веб-сервисом, который доступен на любом устройстве, имеющем браузер и выход в интернет.
В статье речь пойдет как раз о веб-сервисе, с которым можно работать в любом браузере.
Парсер, написанный для компании "Русклимат", автоматически генерирует набор прайс-листов для клиентов компании из прейскурантов поставщиков.
Парсер должен иметь следующий функционал:
Результат работы парсера - это набор доступных для скачивания прайс-листов в форматах MS Excel + XML (каждый в двух форматах).
Пользователь может создать актуальные прайсы для любого клиента, к которому настроен свой профиль выгрузок. Пользователь может не знать, какие исходные данные загружены, все что нужно сделать - несколько кликов.
Для пользователя парсер выглядит как интерактивная html-страница.
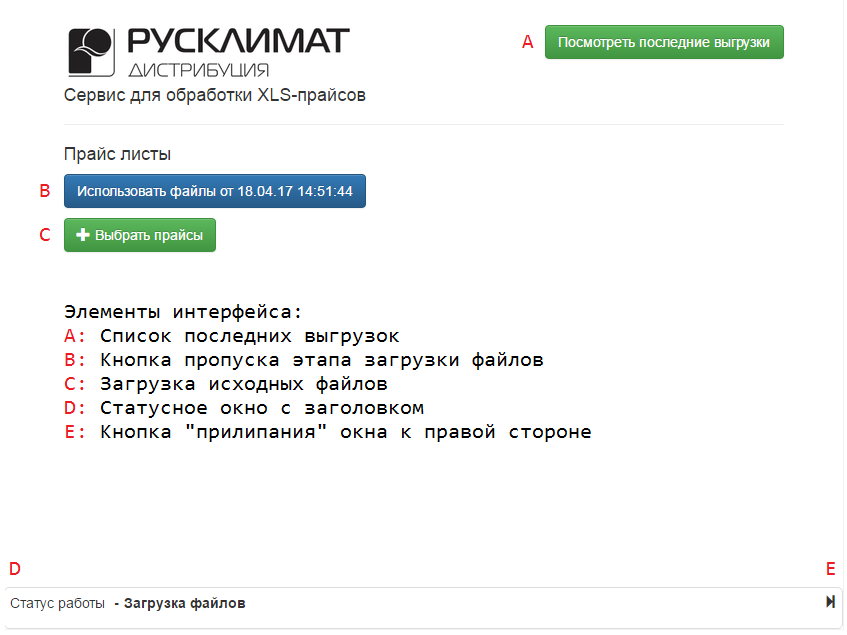 Интерфейс парсера
Интерфейс парсера
На первом этапе пользователь может загрузить исходные файлы, либо воспользоваться ранее загруженными файлами. Дата последней загрузки проставляется в кнопке "Использовать файлы от...". Загрузка происходит с использованием AJAX, во время неё демонстрируется симпатичный прогресс-бар от jquery-file-uploader.
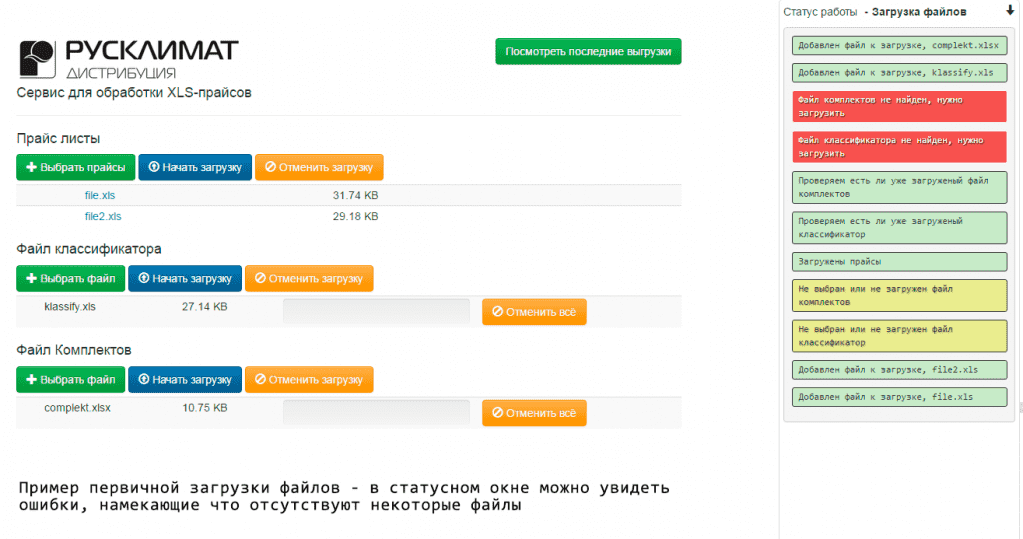 Загрузка файлов
Загрузка файлов
После разбора файлов пользователь может создать профиль выгрузки с разметкой по файлам, разделам, классификаторам и ценам.
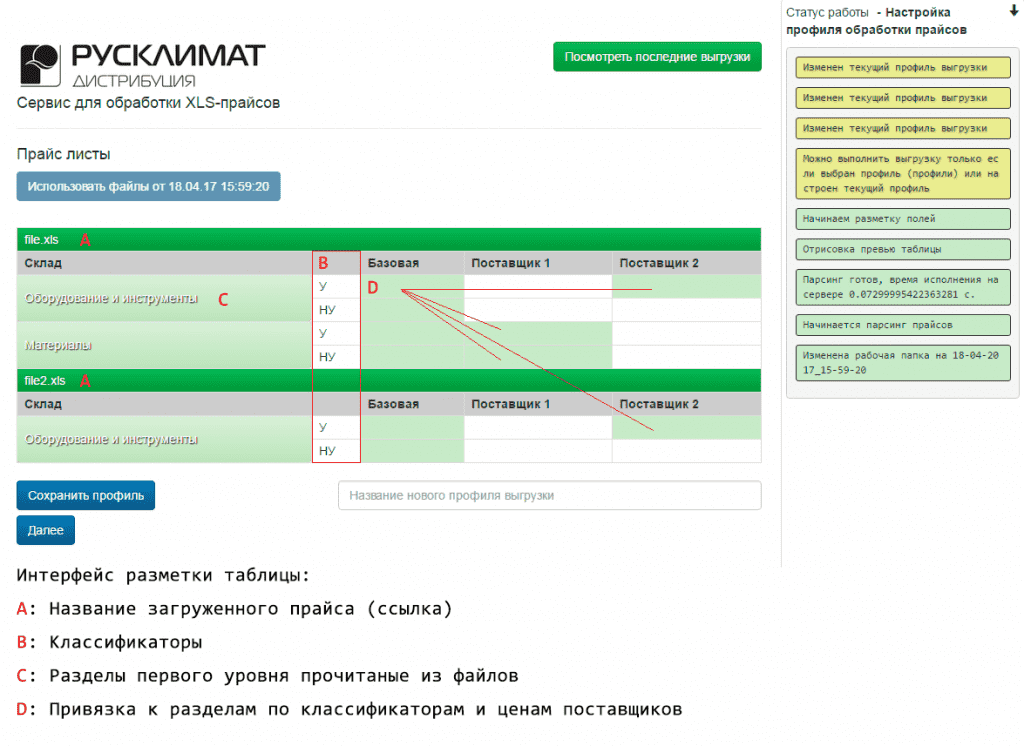 Разметка профилей выгрузки на превью-таблице
Разметка профилей выгрузки на превью-таблице
Можно сохранять профили под различными названиями:
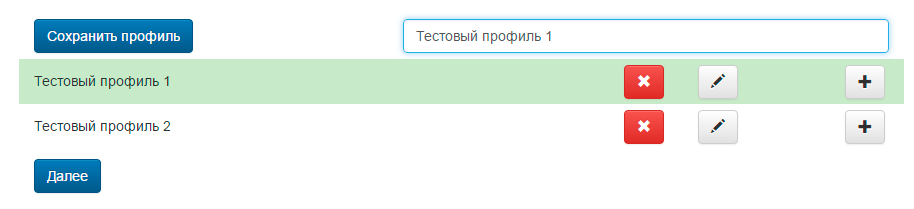 Пример профиля
Пример профиля
Доступна история последних выгрузок.
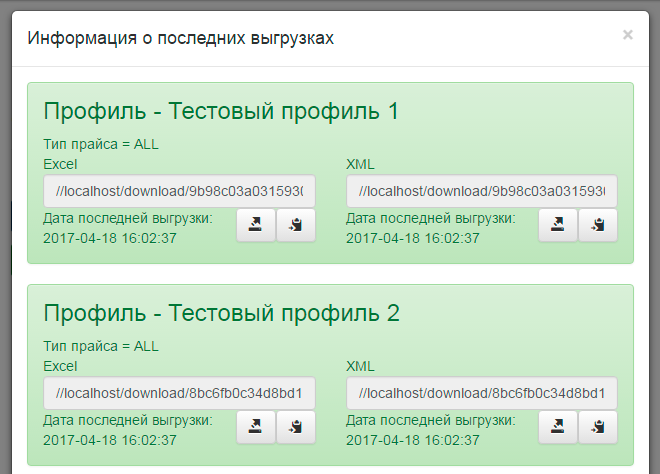 Всплывающее окно со списком последних выгрузок
Всплывающее окно со списком последних выгрузок
Окно статусных сообщений говорит о том, что происходит в данный момент. В нём выводятся статусные сообщения, ошибки, предупреждения, и в нем же появляются диалоги - например, удаление профиля выгрузки, требующее явного подтверждения.
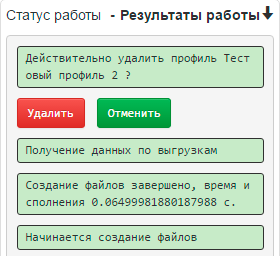 Пример подтверждения в статусном окне при удалении профиля
Пример подтверждения в статусном окне при удалении профиля
Алгоритм работы позволяет разделить рабочие обязанности между разными сотрудниками. К примеру, загрузкой актуальных исходных данных могут заниматься работники склада, а созданием прайс-листов для клиентов - менеджеры, находящиеся в офисе.
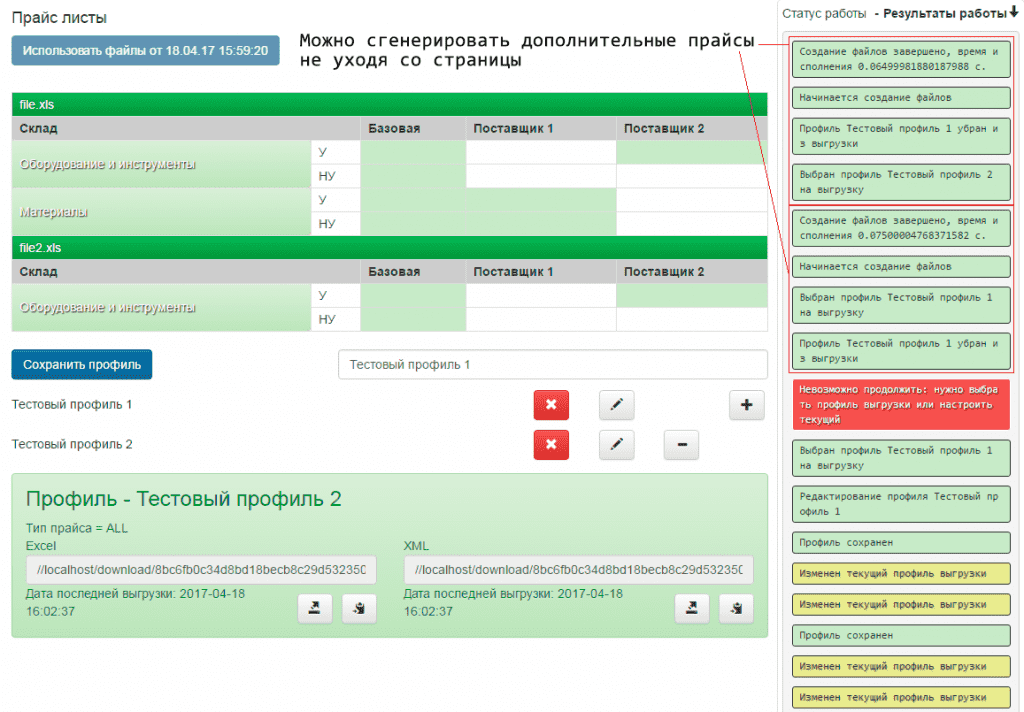 Выбрав другие профили выгрузки можно создать очередной набор прайсов
Выбрав другие профили выгрузки можно создать очередной набор прайсов
В первой версии у генератора был менее гибкий функционал. Как и сейчас, пользователь видел обычную html-страницу. Необходимые файлы загружались в форму и отправлялись на сервер. Через несколько секунд страница перезагружалась, и пользователь видел результат парсера. Файлы скачивались всегда по одной и той же ссылке.
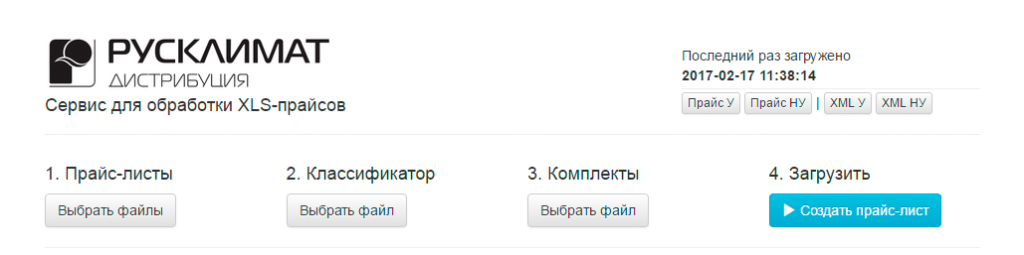 Старый парсер
Старый парсер
Работать с генератором было удобно, пока не появились требования к сохранению истории и настройке профилей. Новый функционал можно было бы организовать на отдельных страницах, однако, тогда пришлось бы расширить клиентскую часть - добавить роутинг и контроллеры. Раздувать клиентскую часть без необходимости не хотелось, поэтому редактирование профилей решено было сделать на той же страничке. В итоге - за страницей следит единственный виджет.
Виджет написан на прототипах, в качестве библиотек используются:
В виджете есть шина событий, после каждой операции на ней публикуется событие. Шина - это объект jquery:
var $eventBus = $({}); Для публикации можно указывать напрямую название события и данные, и добавлять слушателей также по имени события: $eventBus.on('event1 event2 event3', function (event, data) {
switch (event) {
case 'event1':
break;
case 'event2':
break;
case 'event3':
break;
}
});
Однако, в этом есть небольшой минус - нужно заранее перечислять, какие события слушаем, и актуализировать список каждый раз при добавлении событий. С другой стороны, можно публиковать одно и то же событие, а само "название" передавать как параметр данных. Тогда все становится проще: нет нужды актуализировать список "событий", только добавлять ветки switch. В данном случае использование именно switch оправдано - поиск идет по хеш-таблице и выполняется с линейной скоростью. Если бы это была цепочка if/else, то чем "дальше" событие по цепочке, тем медленнее оно бы срабатывало. Хоть и небольшой, но оверхед. $eventBus.on('myCustomEvent', function (event, data) {
switch (data.event) {
case 'event1':
break;
case 'event2':
break;
case 'event3':
break;
}
})
Вывод сообщений в окно статусов сделать в таком случае совсем несложно - все сообщения пишутся в одном месте - на шине в блоках case: одновременно убивается 2 зайца - самоописательный код и нотификация пользователя.
...
case 'state:set:profile-management':
_.getNode('curstep').text('Настройка профиля обработки прайсов');
break;
case 'state:set:pre-saving':
_.getNode('curstep').text('Создание файлов');
break;
case 'state:set:done':
_.getNode('curstep').text('Результаты работы');
_.pub('hide:next');
break;
case 'profile:edit':
_.initProfile(data.id);
_.report('Редактирование профиля ' + data.name);
break;
...
Автоиспользование уже загруженных файлов реализовано следующим образом. Загрузчик jquery file uploader грузит файлы на сервер и в ответ получает их пути. Если эмулировать этот шаг и сразу возвращать пути, можно обойтись и без загрузки - как раз то, что нужно. По клику на кнопку "использовать файлы от" сохраненные пути передаются в виджет и после этого начинается разметка таблиц.
Интересным оказался вопрос о том, как получать подтверждения от пользователей. В нотификаторе им самое место, однако сообщения – это всего лишь текст без логики. Чтобы дать возможность публиковать события в виджете, желательно, чтобы коллбек на кнопку можно было повесить сразу. Решается это несложно - в методе, который отвечает за вывод сообщений, стоит проверка: если пришел обычный текст - обернем его в объект jquery и append в блок сообщений, если же сразу приходит объект jquery - тогда без оберток вставляется сразу в сообщения. Плюс именно append/prepend - события на элементах сохраняются. Если же просто вставлять как текст/html – никакого эффекта не будет. Это тоже можно решить, если повесить коллбек на сам блок сообщений. При вставке в код новых элементов браузер превращает их в объекты DOM, которые могут генерировать события. Потом такие события можно слушать на родительских элементах и определять по каким-то признакам, является ли кликнутый элемент кнопкой подтверждения или отмены.
Полезной возможностью, которую предоставляет event-based архитектура, является то, что можно повторять некоторые события вновь без необходимости начинать весь рабочий процесс заново. В данном случае - можно генерировать множество различных прайсов по разным профилям, в т.ч. по "пользовательскому", который не сохраняется и настраивается только в момент работы. Если есть необходимость сгенерировать дополнительные прайсы - нужно всего лишь выбрать новые профили, не уходя со страницы.
Парсер работает на php и не требует базы данных. Для чтения и записи MS Excel-таблиц используется PHPExcel - мощная библиотека с поддержкой нескольких форматов таблиц. Однако, "ручное" конфигурирование формата таблицы с объединенными ячейками таблицы без видимого интерфейса требует хорошего визуального мышления.
Данные между ajax-вызовами нужно где-то хранить. Для этого на каждую дату создается отдельная папка, в которую складываются загружаемые в начале дня прайсы. При разборе данных вся информация также промежуточно сохраняется в файлах в сериализованном виде. Это удобно - для продолжения работы нужно всего лишь считать файл. С отладкой чуть сложнее - пришлось дописать собственный инструмент разборки промежуточных данных, но с его помощью найти источник ошибки в данных получается намного быстрее.
Пара слов о профилях. Профиль по факту - это сохраненные привязки между ценами и разделами. Но для того чтобы сделать привязку корректной и не путать раздел "Раздел1" и "раздел1" из-за разницы в регистре букв - нужно приводить названия в один регистр через mb_strtolower($sectionName) и хешировать в md5. Такая привязка очень помогает в разметке таблицы для профиля - одинаковые разделы выделяются сразу во всех файлах т.к. у них один и тот же хеш.
В настоящий момент решение продолжает работать, изредка помогая обнаруживать некорректные входные данные.









